When completing an online form, proving that you’re not a robot can be very annoying. Sometimes even frustrating, especially if the website uses reCAPTCHA or a similar implementation of a system that asks you to decipher some cryptic text.
I don’t use reCAPTCHA on this website, but I do encounter it on other websites. So it was heart-warming to learn that Google has released a new implementation of reCAPTCHA called No CAPTCHA reCAPTCHA that doesn’t come with reCAPTCHA’s annoying aspects.
The official announcement has it that “a significant number of users will be able to securely and easily verify they’re human without actually having to solve a CAPTCHA. Instead, with just a single click, they’ll confirm they are not a robot.”
What’s not to like about that? But is it as simple as that? And how does the system know that the entity completing a form is a human and not an automated script? The simplest way to find out is to try and complete an online form protected from bots by No CAPTCHA reCAPTCHA.
Before I relate my experiences with the demoes, I should point out that the developers do concede that “CAPTCHAs aren’t going away just yet.” And that “In cases when the risk analysis engine can’t confidently predict whether a user is a human or an abusive agent, it will prompt a CAPTCHA to elicit more cues, increasing the number of security checkpoints to confirm the user is valid.”
But in cases where the system is able to determine that a user is a human, how does it know? From my tests, here’s how I think the system knows: Prior login information. Cookies don’t seem to play a part in the ability of No CAPTCHA reCAPTCHA to uniquely identify you.
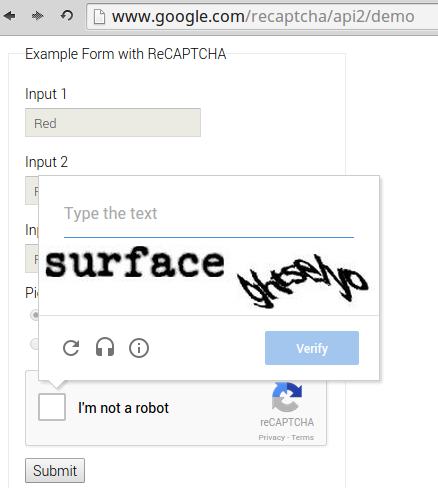
While logged into a Google property and visiting the official demo website, for example, No CAPTCHA reCAPTCHA was able to accurately determine that the entity submitting the form was not a robot. Figure 1 was taken from that attempt.

Figure 1: Passed a No CAPTCHA reCAPTCHA test.
However, visiting the same demo website from browsers that I’ve never used to log into a Google property, the system was not able to identify me. And that’s true whether the browsers were configured to accept Cookies or not.

Figure 2: Failed a No CAPTCHA reCAPTCHA test.
So it appears that the “significant number of users” that “will be able to securely and easily verify they’re human without actually having to solve a CAPTCHA” will be those already logged into the website. For the other very significant number of users that the system cannot uniquely identify, it will try the old technique – shove a reCAPTCHA in there faces.
So the benefit of No CAPTCHA reCAPTCHA is very minimal, unless there’s something that I’m missing.




{kind=link}
CAPTCHA / reCAPTCHA has been a problem for me until I just updated to Ubuntu 17.04. I can’t seem to sign on to anything because the CAPTCHA doesn’t even show up on the page. Preferences does not indicated an on/off switch for it either. I’m going to have to go back to 16.04 or even better 14.04LTS. I enjoy commenting in real time about everything especially politics, and science.
I don’t see what CAPTCHA/reCAPTCHA got to do with the edition of Ubuntu you’re running.
You were indeed missing something. The fallback to text captcha was temporary. When this was released last year, a week or so later the text captcha made room for the image selector. This removed the last traces of the text captcha.
I am trying for past two days to read and enter the letters in the recapcha. I never seen such code in my life in internet. What is that security. I wondered how Google is preparing such quality less product and wasting time and irritating people. Is it providing that much security?
Please make it readable fore mate. It is not security question to answer and remember.
Please
Thanks for publishing and researching this. I thought I was crazy. No captcha yet we still prompt you for the old captcha…huh.
I was thinking may be they are checking a time on the page factor because that is another way behind the scenes to test for automated form submitting.
I rather like the “3+_=7” style.