
Editor: For setting up the Docker Swarm cluster used in this article, the author uses Docker Machine. Keep that in mind because the pre-stable version of Docker has orchestration built-in, so Docker Machine is about to go the way of the dodo.
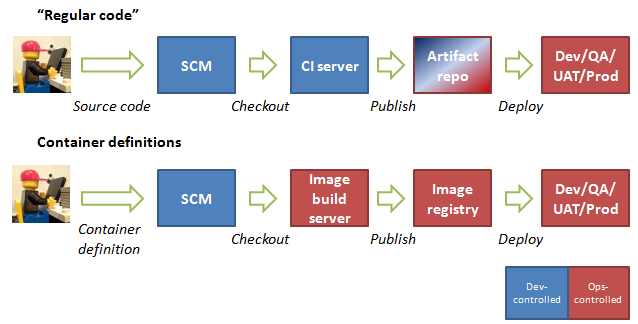
The purpose of this post is to show how powerful and flexible Docker Swarm can be when combined with standard UNIX tools to analyze data in a distributed fashion. To do this, let’s write a simple MapReduce implementation in bash/sh that uses Docker Swarm to schedule Map jobs on nodes across the cluster.
MapReduce is usually implemented when there’s a large dataset to process. For the sake of simplicity and for reproducibility by the reader, we’re using a very small dataset composed of a few megabytes of text files.
This post is not about showing you how to write a MapReduce program. It’s also not about suggesting that MapReduce is best done in this way. Instead, this post is about making you aware that the plain old UNIX tools such as sort, awk, netcat, pv, uniq, xargs, pipe, join, time, and cat can be useful for distributed data processing when running on top of a Docker Swarm cluster.
Read the complete article here.





{kind=link}